

拍拍译是一款由长沙维美通信技术有限公司研发的综合性移动端语言翻译解决方案,它集成了光学字符识别、神经网络机器翻译、语音识别与合成等多项前沿技术,为用户提供跨语言、跨场景的即时沟通与信息获取服务。软件支持全球主流语言的互译,包括但不限于英语、日语、韩语等,其核心价值在于通过文本、语音、图像三种交互模态,无缝衔接学习、工作、旅行等多元场景,以高准确度的实时翻译能力,有效破除语言壁垒,提升信息处理与跨文化交流的效率。
拍拍译软件特色介绍
拍拍译的核心竞争力体现在其深度融合的四大技术特色上,这些特色并非简单的功能堆砌,而是针对用户真实使用场景的精准技术响应。
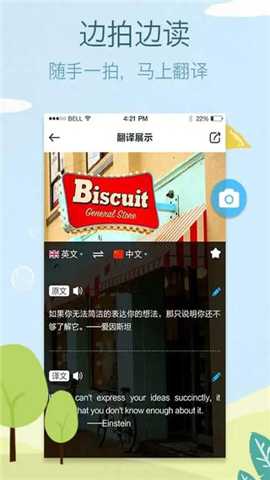
一、多模态融合的即时OCR翻译引擎:这是拍拍译的基石功能。其采用的并非简单的图像文字提取,而是集成了场景感知与版面分析的增强型光学字符识别技术。当用户摄像头对准目标文本时,系统能快速进行图像预处理、文字区域检测、字符分割与识别,随后将识别出的文本送入神经网络翻译模型。该过程优化了复杂背景、低光照、字体多样及非标准排版下的识别率,尤其对于菜单、路牌、说明书等印刷体文本,能实现所见即所译,将传统需要手动输入再翻译的多步操作简化为一步,极大提升了信息获取速度。
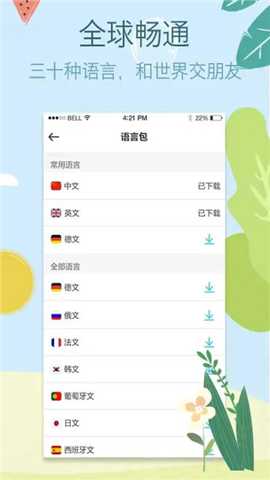
二、基于离线神经网络的翻译能力:针对移动环境下网络不稳定或无网络的痛点,拍拍译内置了轻量化的离线神经网络翻译模型。用户可预先下载特定语言对的离线数据包,该数据包包含了经过压缩和优化的模型参数与词库。在离线状态下,翻译请求将在本地设备端完成计算,无需连接云端服务器。这不仅保障了用户在境外旅行、网络信号薄弱区域(如地铁、山区)的通信连续性,也有效保护了用户翻译内容的隐私性,避免了敏感信息上传至云端可能带来的数据安全风险。
三、低延迟的端到端语音对话翻译:该功能实现了接近实时的双向语音翻译。其技术栈整合了自动语音识别,将语音流实时转换为文本;通过在线或离线的机器翻译引擎进行文本转换;利用语音合成技术将翻译后的文本转换为目标语言语音输出。整个流程经过深度优化,最小化系统延迟,实现近乎自然的对话节奏。这对于面对面交流、电话沟通等场景至关重要,实现边说边译,形成流畅的对话回合,而非僵硬的单句等待,从而真正促进跨语言人际沟通。
四、上下文感知与领域自适应翻译:拍拍译的翻译引擎并非简单的词对词替换,而是引入了注意力机制和上下文理解模型。系统能够分析句子甚至段落级别的语境,以处理一词多义、代词指代等问题,提供更符合目标语言习惯的译文。针对某些通用领域(如餐饮、购物、旅游)或通过用户反馈,模型能够进行一定程度的自适应优化,在面对特定领域的术语或惯用语时,提供比通用翻译模型更准确、更地道的翻译结果,提升了专业场景下的实用价值。
拍拍译软件功能
拍拍译的具体功能是其技术特色的具象化体现,每一项功能都解决一个或多个具体的用户痛点。
1. 拍照翻译/取词翻译: 解决看不懂的印刷文字痛点。用户遇到外文书籍、文件、商品标签、餐厅菜单、路牌指示时,无需手动键入冗长或陌生的文字,只需启动该功能扫描,即可在屏幕上获得叠加在原图上的翻译结果或单独的译文文本。这彻底改变了处理大量印刷体外文信息的传统方式,将信息解码时间从分钟级缩短至秒级。
2. 语音实时对话翻译: 解决面对面跨语言交流不畅的痛点。在旅行问路、酒店入住、商务洽谈或外语口语练习中,用户只需选择对话模式,分别设定双方语言,即可通过语音输入进行连续对话。软件自动识别说话人语种并翻译播放,将复杂的语言沟通简化为标准的听-说模式,降低了因语言不通导致的沟通焦虑和误解可能性。
3. 文本输入翻译: 解决需要精确翻译长句或段落的痛点。当用户需要翻译电子邮件、社交媒体内容、学习资料或撰写外文文案时,可以手动输入或粘贴文本。该功能提供完整的编辑界面,支持大段文字处理,并能利用上下文感知模型提供高质量的笔译结果,适用于对翻译准确性和语言质量要求较高的非即时性场景。
4. 离线翻译包管理: 解决无网络环境下翻译需求的痛点。用户可在Wi-Fi环境下,根据行程或学习计划,提前下载所需语言对的离线包。该功能将翻译能力从对网络连接的依赖中解放出来,确保了核心翻译功能在任何环境下的可用性,是差旅人士和户外工作者的必备保障。
5. 翻译历史与收藏管理: 解决信息复用与学习回顾的痛点。软件自动保存用户的翻译记录,并允许用户对重要的翻译结果进行收藏和分类。这对于语言学习者而言,可以构建个人的生词本和例句库;对于商务人士,可以积累常用的专业术语和表达,实现知识的沉淀与高效再利用。
6. AR实时取景翻译: 作为拍照翻译的进阶功能,它解决了动态场景中连续获取翻译信息的痛点。用户无需反复拍照,只需通过摄像头取景框对准周围环境,软件即可实时识别画面中的文字并进行叠加翻译。这在参观博物馆、浏览街头广告或阅读复杂设备面板时,能提供沉浸式、不间断的翻译体验。
未来前景与技术演进
拍拍译所代表的移动翻译工具,其未来发展潜力将深度融入人工智能技术的演进浪潮。短期来看,技术的进步将聚焦于提升现有功能的体验边界。翻译质量将随着大规模多语言预训练模型的迭代而持续精进,特别是在文化隐喻、俗语和专业术语的翻译上,将更加精准和地道。多模态融合将更加深入,未来可能实现结合视觉场景理解的翻译,识别图片中的物体、场景并结合文本,生成更具描述性和情境相关性的译文。
从中期展望,软件将向个性化与主动服务演进。通过分析用户的使用习惯、专业领域和语言偏好,翻译模型可以进行个性化微调,成为用户的专属翻译官。结合可穿戴设备(如AR眼镜、智能耳机),翻译功能将变得更加无缝和隐形,实现真正的第一视角同声传译,彻底解放用户的双手。
从长期生态构建来看,拍拍译这类工具可能演变为跨语言交互的操作系统底层服务。其API将深度集成到其他应用(如社交软件、办公套件、浏览器、智能家居)中,成为数字世界默认的语言转换层。用户在任何数字界面中与外语内容交互时,都能获得即时、流畅的母语体验。在元宇宙、全球实时协作等新兴场景中,低延迟、高保真的跨语言语音与文字交流将成为基础设施,其技术核心正是当前移动翻译软件所持续锤炼的实时语音识别、翻译与合成能力。
从技术伦理与可及性角度考量,未来的发展也需关注对低资源语言的支持,通过迁移学习等技术缩小语言数字鸿沟,以及确保算法公平性,避免翻译中的文化偏见。拍拍译作为实用化工具,其演进路径清晰地指向一个目标:让语言不再成为人类知识与情感自由流动的障碍,而这背后是计算语言学、人工智能与硬件技术协同发展的宏大叙事。








